



































spark基礎知識介紹

Spark是一種開源集群計算環境,與Hadoop相似但又有所不同。Apache Spark最初是由加州大學伯克利分銷的AMP實驗室開發出來的,后來成為Apache的開源項目之一,作為專門為大規模數據處理而設計的快速通用型計算引擎來使用。與MapReduce技術相比,Spark有著多種優勢,如提供了統一全面的框架、大大提高了應用運行速度、可以快速使用Java等語言來編寫程序等,目前Spark形成一個應用廣泛、發展高速的生態系統。接下來就讓我們一起來了解下Spark的性能特點、運行模式、運行特點以及體系架構等知識。
目錄
1. spark性能特點
2. spark運行模式
3. spark運行特點
4. spark體系架構
5. spark與hadoop的關系
-

spark性能特點
1、專注性。由于高級API剝離了對于集群本身的關注,所以spark開發者可以專注于應用所需要做的計算本身。
2、速度快。Spark支持復雜算法和交互式計算,運行速度快。
3、通用性。Spark是一個通用引擎,因此可以用來完成如文本處理、SQL查詢等運算。
4、支持多種資源管理器。如Hadoop YARN、Apache Mesos等管理器都支持使用。 -

spark運行模式
1、spark的運行模式是多種多樣的,并不限于一種,可以按需選擇。
2、以單機方式部署時,spark可以用本地模式運行或者偽分布模式運行。
3、部署在分布式集群時,也可以根據集群的實際選擇不同的運行模式。底層資源調度既可以使用spark內建的獨立集群運行模式,也可以依賴外部資源調度框架。 -
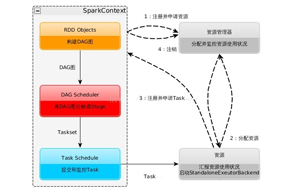
spark運行特點
1、除非在外部存儲系統寫入數據,否則Spark Application就不能跨應用共享數據。
2、spark的運行和資源管理器是沒有關系的,只需獲取executor進程并保持通信即可。
3、提交SparkContext的Client需靠近運行Executor的節點,而且最好在同一個Rack里。
4、Task采用的優化機制是數據本地性和準側執行。 -
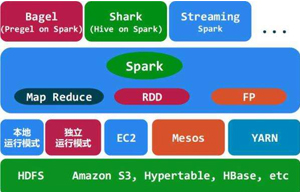
spark體系架構
Spark體系架構主要有三個組件。
1、數據存儲。Spark使用HDFS文件系統來存儲數據。
2、資源管理。Spark有多種不同的部署方式,可以部署在一個單獨服務器上,也可以部署在分布式計算框架上,如Mesos等。
3、API。Spark提供三種程序設計語言的API,分別是Java、Scala和Python。開發者可以利用標準的API接口來創建基于Spark的應用。 -

spark與hadoop的關系
1、spark自身是沒有提供分布式文件系統的,其分析大部分都需要依賴于Hadoop的分布式文件系統,也就是HDFS。
2、Mapreduce是Hadoop的分布式計算模塊,Mapreduce和spark都可以計算數據,但Mapreduce比spark速度要慢一些,且功能也不如spark豐富。
3、spark可以看作是Hadoop MapReduce的替代品,用來提供一個全面、統一的管理大數據用例和需求的解決方案。
- 關于cms系統設計的小知識
- 中企動力提醒:網絡違法案例,等保刻不容緩
- 中企動力:網站運營怎么做之統計后臺篇
- 中企動力:網站運營難不難?
- 中企動力在5G時代給企業的小建議
- 中企動力:個人建站需要哪些能力?
- 中企動力:公司網站被黑怎么辦?
- 中小企業數字經濟論壇召開,中企動力助力企業數字化轉型
- 中企動力:教你如何建立“新型”企業網站
- 肉驢養殖利潤效益分析
- 在線建網站靠譜嗎?在線建網站常問的5個問題!
- 營銷廣告人員必看,市場分析包括哪些方面?
- 揭秘:在線建網站內幕曝光,80%老板都被騙了
- 優秀的廣告設計理念需要具備的基本要素
- 廣告聯盟的特點
- 數據庫在建立信息管理系統中的特點
- 抖音和今日頭條的關系淺析
- 你真的會寫品牌推廣計劃嗎?
- 你了解linux運維工程師嗎
- 微信推廣平臺如何起到良好的宣傳作用





